[python]基于鼠标轨迹的人机验证分类问题(赛氪——大数据挑战赛)baseline
前言
一个月的mis系统开发弄得头晕眼花,耽误了不少时间,好在这个比赛时间周期很长,而且题目不算太难,个人感觉对新人比较友好(除了每天只能上传一次以外)。另一方面,做开发的时候忙里偷闲提了一些特征,只用经典的决策树和4个特征就达到了将近60分,顿时信心爆棚(虽然说二分类问题瞎蒙可能就是50分。。。/)。
![]()
受到一些dalao的启发,考虑在不提特征的情况下进行分类,把这个当做baseline顺便为以后做预测增加可能性也是极好的。
【本文适合有一些数据挖掘基础的小白观看,dalao请无视】
比赛数据
本题目数据来源于某人机验证产品采集的鼠标轨迹,经过脱敏处理,数据分为3部分(数据量分别为3000条,10万,200万)。
训练数据表名称:dsjtzs_txfz_training
| 字段 | 类型 | 解释 |
| a1 | bigint | 编号id |
| a2 | string | 鼠标移动轨迹(x,y,t) |
| a3 | string | 目标坐标(x,y) |
| label | string | 类别标签:1-正常轨迹,0-机器轨迹 |
其中t为采样时那一时刻的时间(脱敏)。评分方式就不列了,因为最后比赛会更改积分规则,但是有心人可以根据现有的评分规则推测出自己提交结果的正确数目☺
数据分析
下载完数据集后,打开txt。训练集的数据格式为[id 若干个x,y,t坐标 target坐标 label],测试集仅仅少了一个label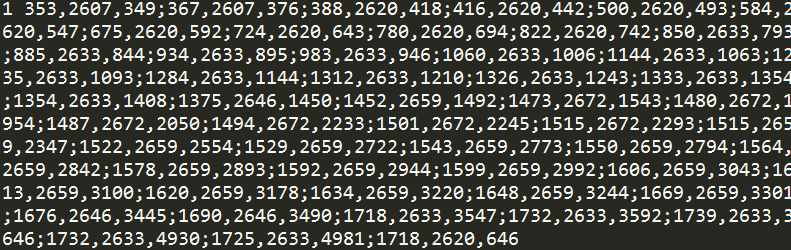
话不多说,直接从文件中读取数据。
使用pandas读取文件很方便,直接读取后保存在dataframe中
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
from matplotlib.pyplot import plot,savefig
TRAIN_DATA='../data/dsjtzs_txfz_training.txt'
TEST_DATA='../data/dsjtzs_txfz_test1.txt'
TRAIN='../data/train.txt'
TEST='../data/test.txt'
RESULT='../tmp/res'
#读取文件
def read_file(filepath):
data = pd.read_table(filepath,header=None,encoding='utf-8',delim_whitespace=True)
return data
现在dataframe中数据的格式为
id x,y,t;x,y,t;…x,y,t target_X,target_y label
第二列由于x,y,t…是一个字符串,而且由分号隔开,不方便在dataframe继续操作,所以这里直接遍历dataframe取出x,y,t分别存在三个list
借助之前的read_file函数,新建一个创建标准数据集的函数loadDataSets:
(考虑这个函数要处理训练集和测试集,而测试集没有标签,所以给测试集默认赋标签为1)
#创建样本集
def loadDataSets(filepath,outpath):
data=read_file(filepath)
for ix,row in data:
trail_x,trail_y,trail_t=get_trail(row)
target=str(row[2]).split(',')
label=str(row[3]) if len(row)==4 else -1#默认测试集标签为-1
再补上get_trail的实现方法:
#获取移动轨迹坐标和时间
def get_trail(row):
trail_x,trail_y,trail_t=[],[],[]
loc=str(row[1]).split(';')
for x_y_t in loc:
x_y=x_y_t.split(',')
if len(x_y) >=3:
trail_x.append(x_y[0])
trail_y.append(x_y[1])
trail_t.append(x_y[2])
return trail_x,trail_y,trail_t
但是这样当然不算完,只是获取了轨迹的x,y,t三个list,如何能作为训练数据?
在不提取特征的情况下,最简单的方式就是把所有的x坐标当做特征,用这些特征产生训练模型(不用t是因为t的维度和x不一样,一个是时间,一个是坐标点,后面再考虑把y,t变成特征加入,不过要做归一化,看看怎么取效果更好)
还有一个问题就是并非所有样本的坐标数都一样,简单统计后发现所有样本的坐标数不超过300个,所以这里默认给坐标数量不够的样本全部填充0。
最后,为了方便后续处理,把产生的特征放入dataframe中。
更改loadDataSets的代码:
#创建样本集
def loadDataSets(filepath,outpath):
train_data=read_file(filepath)
col_name=['id']#col_name是dataframe每一列的名称
all_data=[]
for i in range(300):
col_name.append('x'+str(i))
col_name.append('target_x')
col_name.append('label')
for ix, row in train_data.iterrows():
each_row=[]
each_row.append(row[0])#id
trail_x,trail_y,trail_t=get_trail(row)
target=str(row[2]).split(',')
label=str(row[3]) if len(row)==4 else 1#默认测试集标签为1
loc_len=len(trail_x)
for i in range(300-loc_len):#前位全部填充0
each_row.append(0)
for i in range(loc_len):#后位填充真实数据
each_row.append(trail_x[i])
each_row.append(target[0])#终点x坐标
each_row.append(label)#标签
all_data.append(each_row)#一个样本的特征list添加到总样本特征list
dataSet=pd.DataFrame(all_data)
dataSet.columns=col_name
return dataSet
获取了特征以后,新建一个main函数测试输出一下:
#主函数
if __name__ == "__main__":
dataSet=loadDataSets(TRAIN_DATA)
print dataSet
输出结果: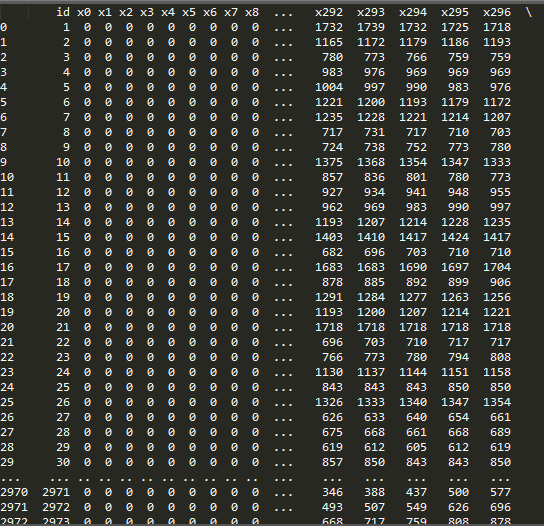
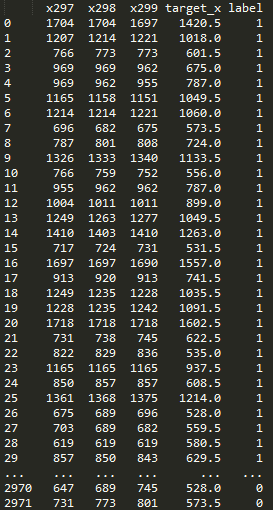
特征是得到了,产生特征集的过程很慢,尤其是对测试集10万数据的处理,所以把每次代码运行时没有变化的庞大数据及时存档尤为重要。做起来也很简单,在loadDataSets函数的return之间添加:
dataSet.to_csv(outpath,index=False)
之后再运行一次代码,产生了train.txt后就可以注释掉main中的loadDataSets了
现在还需要做的是,创建交叉验证集(预估分类结果的准确性,这样可以根据交叉验证的结果调整分类器的参数)。同时为了让整个流程代码不要过于臃肿,把对训练集和测试集的操作放在一个函数中,创建create_train_and_test:
#创建训练集和测试集
def create_train_and_test(model='train'):
train_data=pd.read_csv(TRAIN)
train=train_data.drop(['id','label'],axis=1)#特征集不能有id和label
label=train_data['label']#标签集
if model=='train':
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(train, label, test_size = 0.4)
elif model=='test':
x_train=train
y_train=label
test_data=pd.read_csv(TEST)
x_test=test_data.drop(['id','label'],axis=1)
y_test=test_data['label']
return x_train,y_train,x_test,y_test
使用sklearn提供的分类器分类,这里先尝试使用knn,创建algorithm并修改main函数:
#分类并预测
def algorithm(x_train,y_train,x_test,y_test):
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier()
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
from sklearn.metrics import classification_report
print classification_report(y_test, y_pred)
#主函数
if __name__ == "__main__":
#train=loadDataSets(TRAIN_DATA)
x_train,y_train,x_test,y_test=create_train_and_test('train')
algorithm(x_train,y_train,x_test,y_test)
交叉验证的结果:
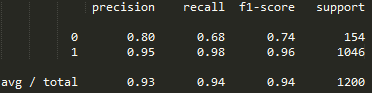
sklearn的算分方式和官方不同,但是分类0的准确率和召回率是可以用的。按照官方的方式再算一遍,得分为:
5PR/(2P+3R)*100=5*0.80*0.68/(2*0.80+3*0.68)*100=2.72/3.64*100=74.72%
最后,对测试集做相同的处理,并把结果导出到文件,添加write_to_result,并改写main和algorithm:
#写文件
def write_to_result(y_pred,model='train'):
res=[i+1 for i in range(len(y_pred)) if y_pred[i]==0]
res=[str(int(i)) for i in res]
import datetime
import time
i = str(datetime.datetime.now())
i=i.replace(':','-')
i=i.replace(' ','_')
i=i.replace('.','-')
f=open(RESULT+'_'+model+'_'+i+'.txt','w')
f.write('\n'.join(res))
f.close()
#分类并预测
def algorithm(x_train,y_train,x_test,y_test,model='train'):
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier()
clf.fit(x_train,y_train)
y_pred = clf.predict(x_test)
write_to_result(y_pred,model)
from sklearn.metrics import classification_report
print classification_report(y_test, y_pred)
if __name__ == "__main__":
train=loadDataSets(TRAIN_DATA)
test=loadDataSets(TEST_DATA)
model='test'
x_train,y_train,x_test,y_test=create_train_and_test(model)
algorithm(x_train,y_train,x_test,y_test,model)
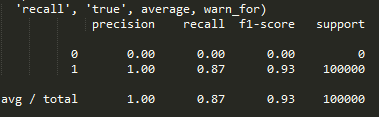
因为测试集不能判断正确率,所以只要打开相关的结果文件res_test…..txt大致看一看预测数量有多少就行了,较好的结果在20000个左右。
至此,分类和预测都已经完成,后续工作需要慢慢考虑了。
得分:
![]()
To be continue…