pandas常用函数记录
1,369 Views
函数名:pandas.read_csv()
作用:读取csv文件内容
返回值:dataFrame
| 常用参数 | 取值 | 作用 |
| filepath_or_buffer | str | 读取文件的路径 |
| sep | char | 切分字符串的标识符 |
| header | infer或None | 判断读取的csv是否有标题行 |
| chunksize | int | 按指定大小分块读文件 |
| encoding | str | 按指定编码读文件 |
函数名:pandas.concat()
作用:多个对象连接为一个对象
返回值:obj(dataFrame等)
| 常用参数 | 取值 | 作用 |
| objs | dataframe/series/… | 读取对象集合 |
| ignore_index | bool | 保存/取消索引 |
函数名:pandas.DataFrame.groupby()
作用:按指定要求将dataframe划分成组
返回值:obj(Groupby)
| 常用参数 | 取值 | 作用 |
| by | dataframe中的某几列名 | 分组的依据 |
| as_index | bool | 输出风格 |
函数名:pandas.DataFrame.apply()
作用:统计分组后的累计信息
返回值:obj(dataframe)
| 常用参数 | 取值 | 作用 |
| func | 函数 | 调用函数对dataframe操作 |
| as_index | bool | 输出风格 |
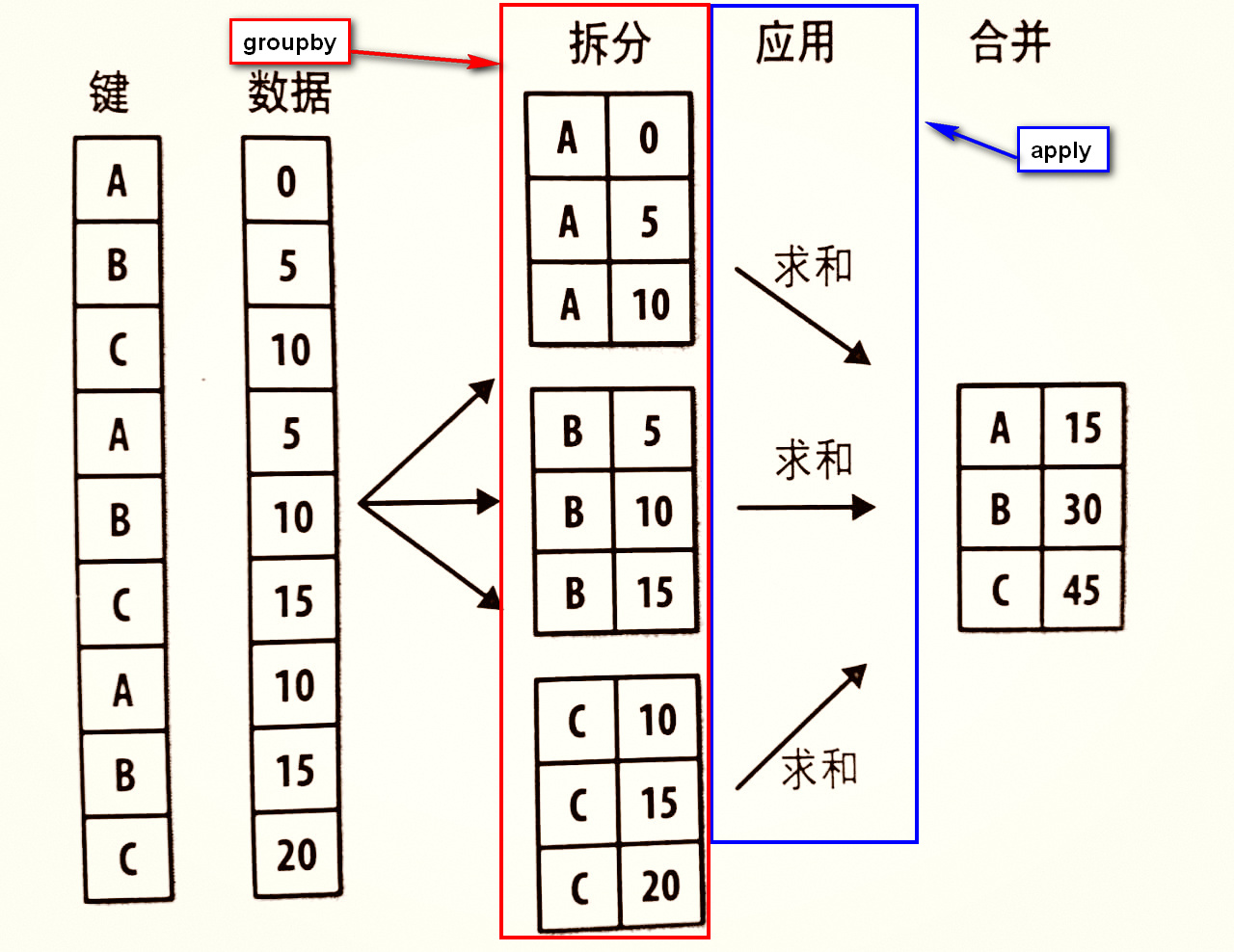
将groupby和apply结合起来,是常用的处理方式,一张图能很简单的说明用法
函数名:pandas.dataframe.ix()
作用:按照索引的方式读取dataframe
返回值:dataFrame
| 常用参数 | 取值 | 作用 |
| p1 | condition | 依据p1对选取的列筛选 |
| p2 | string或int | 选取 dataframe的p2列 |
函数名:pandas.dataframe.isin(obj)
作用:从dataframe筛选出在obj里出现的数据项
返回值:dataFrame
| 常用参数 | 取值 | 作用 |
| values |
list或dict或dataframe | 按照values对dataframe筛选,其中values=list为包含筛选,其他为一一对应筛选 |
函数名:pandas.dataframe.merge()
作用:两个dataframe合并
返回值:dataFrame
| 常用参数 | 取值 | 作用 |
| left | dataframe | 用于合并的dataframe |
| right | dataframe | 用于合并的dataframe |
| on | (dataframe row name) | 按照dataframe的某几列值合并 |
| how | inner/left/right/outer | 选择合并的方式 |